THE DATABASE APPROACH
So, how do we overcome the flaws of file processing? No, we don’t call Ghostbusters,
but we do something better: We follow the database approach. We first begin by defining
some core concepts that are fundamental in understanding the database approach
to managing data. We then describe how the database approach can overcome the limitations of the file processing approach.
Data Models
Designing a database properly is fundamental to establishing a database that meets the
needs of the users. Data models capture the nature of and relationships among data
and are used at different levels of abstraction as a database is conceptualized and
designed. The effectiveness and efficiency of a database is directly associated with the
structure of the database. Various graphical systems exist that convey this structure and
are used to produce data models that can be understood by end users, systems analysts,
and database designers. Chapters 2 and 3 are devoted to developing your understanding
of data modeling, as is Chapter 13, which addresses a different approach using
object-oriented data modeling. Atypical data model is made up entities, attributes, and
relationships and the most common data modeling representation is the entity-relationship model. A brief description is presented below. More details will be forthcoming in Chapters 2 and 3.
ENTITIES
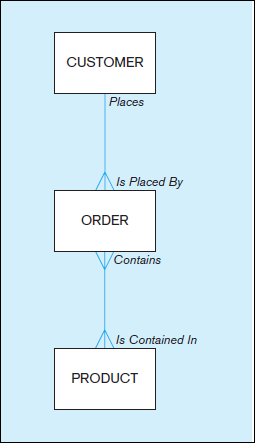
Customers and orders are objects about which a business maintains information.
They are referred to as “entities.” An entity is like a noun in that it describes a
person, a place, an object, an event, or a concept in the business environment for which
information must be recorded and retained. CUSTOMER and ORDER are entities in
Figure 1-3a. The data you are interested in capturing about the entity (e.g., Customer
Name) is called an attribute. Data are recorded for many customers. Each customer’s
information is referred to as an instance of CUSTOMER.
RELATIONSHIPS
A well-structured database establishes the relationships between entities that exist in organizational data so that desired information can be retrieved. Most relationships are one-to-many (1:M) or many-to-many (M:N). A customer can place (the Places relationship) more than one order with a company. However, each order is usually associated with (the Is Placed By relationship) a particular customer.
Figure 1-3a shows the 1:M
relationship of customers who may place one or more orders;
the 1:M nature of the relationship is marked by the crow’s foot attached to the rectangle
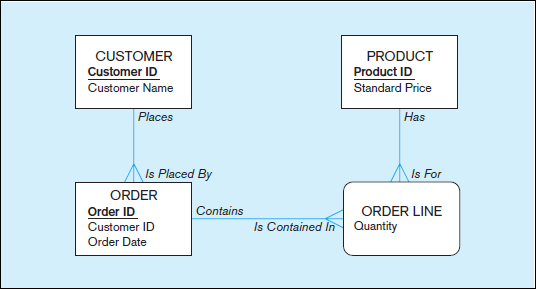
(entity) labeled ORDER. This relationship appears to be the same in Figures 1-3a and
1-3b. However, the relationship between orders and products is M:N. An order may be
for one or more products, and a product may be included on more than one order. It is
worthwhile noting that Figure 1-3a is an enterprise-level model, where it is necessary to
include only the higher-level relationships of customers, orders, and products. The project-
level diagram shown in Figure 1-3b includes additional level of details, such as the
further details of an order.
Relational Databases
Relational databases establish the relationships between entities by means of common
fields included in a file, called a relation. The relationship between a customer and the
customer’s order depicted in the data models in Figure 1-3 is established by including the customer number with the customer’s order. Thus, a customer’s identification number is
included in the file (or relation) that holds customer information such as name, address,
and so forth. Every time the customer places an order, the customer identification number
is also included in the relation that holds order information. Relational databases use the
identification number to establish the relationship between customer and order.
So, how do we overcome the flaws of file processing? No, we don’t call Ghostbusters,
but we do something better: We follow the database approach. We first begin by defining
some core concepts that are fundamental in understanding the database approach
to managing data. We then describe how the database approach can overcome the limitations of the file processing approach.
Data Models
Designing a database properly is fundamental to establishing a database that meets the
needs of the users. Data models capture the nature of and relationships among data
and are used at different levels of abstraction as a database is conceptualized and
designed. The effectiveness and efficiency of a database is directly associated with the
structure of the database. Various graphical systems exist that convey this structure and
are used to produce data models that can be understood by end users, systems analysts,
and database designers. Chapters 2 and 3 are devoted to developing your understanding
of data modeling, as is Chapter 13, which addresses a different approach using
object-oriented data modeling. Atypical data model is made up entities, attributes, and
relationships and the most common data modeling representation is the entity-relationship model. A brief description is presented below. More details will be forthcoming in Chapters 2 and 3.
ENTITIES
Customers and orders are objects about which a business maintains information.
They are referred to as “entities.” An entity is like a noun in that it describes a
person, a place, an object, an event, or a concept in the business environment for which
information must be recorded and retained. CUSTOMER and ORDER are entities in
Figure 1-3a. The data you are interested in capturing about the entity (e.g., Customer
Name) is called an attribute. Data are recorded for many customers. Each customer’s
information is referred to as an instance of CUSTOMER.
RELATIONSHIPS
A well-structured database establishes the relationships between entities that exist in organizational data so that desired information can be retrieved. Most relationships are one-to-many (1:M) or many-to-many (M:N). A customer can place (the Places relationship) more than one order with a company. However, each order is usually associated with (the Is Placed By relationship) a particular customer.
Figure 1-3a shows the 1:M
relationship of customers who may place one or more orders;
the 1:M nature of the relationship is marked by the crow’s foot attached to the rectangle
(entity) labeled ORDER. This relationship appears to be the same in Figures 1-3a and
1-3b. However, the relationship between orders and products is M:N. An order may be
for one or more products, and a product may be included on more than one order. It is
worthwhile noting that Figure 1-3a is an enterprise-level model, where it is necessary to
include only the higher-level relationships of customers, orders, and products. The project-
level diagram shown in Figure 1-3b includes additional level of details, such as the
further details of an order.
Relational Databases
Relational databases establish the relationships between entities by means of common
fields included in a file, called a relation. The relationship between a customer and the
customer’s order depicted in the data models in Figure 1-3 is established by including the customer number with the customer’s order. Thus, a customer’s identification number is
included in the file (or relation) that holds customer information such as name, address,
and so forth. Every time the customer places an order, the customer identification number
is also included in the relation that holds order information. Relational databases use the
identification number to establish the relationship between customer and order.
Database Management Systems
Adatabase management system (DBMS) is a software system that enables the use of a
database approach. The primary purpose of a DBMS is to provide a systematic method
of creating, updating, storing, and retrieving the data stored in a database. It enables
end users and application programmers to share data, and it enables data to be shared
among multiple applications rather than propagated and stored in new files for every
new application (Mullins, 2002). A DBMS also provides facilities for controlling data access, enforcing data integrity, managing concurrency control, and restoring a database.
We describe these DBMS features in detail in Chapter 11.
Now that we understand the basic elements of a database approach, let us try to
understand the differences between a database approach and file-based approach. Let
us begin by comparing Figures 1-2 and 1-4. Figure 1-4 depicts a representation (entities)
of how the data can be considered to be stored in the database. Notice that unlike Figure
1-2, in Figure 1-4 there is only one place where the CUSTOMER information is stored
rather than the two Customer Master Files. Both the Order Filling System and the
Invoicing System will access the data contained in the single CUSTOMER entity.
Further, what CUSTOMER information is stored, how it is stored and how it is accessed
is likely not closely tied to either of the two systems. All of this enables us to achieve the
advantages listed in the next section. Of course, it is important to note that a real life
database will likely include thousands of entities and relationships among them.
Adatabase management system (DBMS) is a software system that enables the use of a
database approach. The primary purpose of a DBMS is to provide a systematic method
of creating, updating, storing, and retrieving the data stored in a database. It enables
end users and application programmers to share data, and it enables data to be shared
among multiple applications rather than propagated and stored in new files for every
new application (Mullins, 2002). A DBMS also provides facilities for controlling data access, enforcing data integrity, managing concurrency control, and restoring a database.
We describe these DBMS features in detail in Chapter 11.
Now that we understand the basic elements of a database approach, let us try to
understand the differences between a database approach and file-based approach. Let
us begin by comparing Figures 1-2 and 1-4. Figure 1-4 depicts a representation (entities)
of how the data can be considered to be stored in the database. Notice that unlike Figure
1-2, in Figure 1-4 there is only one place where the CUSTOMER information is stored
rather than the two Customer Master Files. Both the Order Filling System and the
Invoicing System will access the data contained in the single CUSTOMER entity.
Further, what CUSTOMER information is stored, how it is stored and how it is accessed
is likely not closely tied to either of the two systems. All of this enables us to achieve the
advantages listed in the next section. Of course, it is important to note that a real life
database will likely include thousands of entities and relationships among them.
Advantages of the Database Approach
The primary advantages of a database approach, enabled by DBMSs, are summarized
in Table 1-3 and described next.
The primary advantages of a database approach, enabled by DBMSs, are summarized
in Table 1-3 and described next.

PROGRAM-DATA INDEPENDENCE
The separation of data descriptions (metadata) from the application programs that use the data is called data independence. With the database approach, data descriptions are stored in a central location called the repository.
This property of database systems allows an organization’s data to change and evolve
(within limits) without changing the application programs that process the data.
PLANNED DATA REDUNDANCY
Good database design attempts to integrate previously separate (and redundant) data files into a single, logical structure. Ideally, each primary fact is recorded in only one place in the database. For example, facts about a product, such as Pine Valley oak computer desk, its finish, price, and so forth are recorded together in one place in the Product table, which contains data about each of Pine Valley’s products. The database approach does not eliminate redundancy entirely, but it enables the designer to control the type and amount of redundancy. At other times it may be desirable to include some limited redundancy to improve database performance, as we will see in later chapters.
IMPROVED DATA CONSISTENCY
By eliminating or controlling data redundancy, we greatly reduce the opportunities for inconsistency. For example, if a customer’s address is stored only once, we cannot disagree about the customer’s address. When the customer’s address changes, recording the new address is greatly simplified because the address is stored in a single place. Finally, we avoid the wasted storage space that results from redundant data storage.
IMPROVED DATA SHARING
A database is designed as a shared corporate resource. Authorized internal and external users are granted permission to use the database, and each user (or group of users) is provided one or more user views into the database to facilitate this use. Auser view is a logical description of some portion of the database that is required by a user to perform some task. A user view is often developed by identifying a form or report that the user needs on a regular basis. For example, an employee working in human resources will need access to confidential employee data; a customer needs access to the product catalog available on Pine Valley’s Web site. The views for the human resources employee and the customer are drawn from completely different areas of one unified database.
INCREASED PRODUCTIVITY OF APPLICATION DEVELOPMENT
A major advantage of the database approach is that it greatly reduces the cost and time for developing new business applications. There are three important reasons that database applications can often be developed much more rapidly than conventional file applications:
1. Assuming that the database and the related data capture and maintenance applications
have already been designed and implemented, the application developer
can concentrate on the specific functions required for the new application, without
having to worry about file design or low-level implementation details.
2. The database management system provides a number of high-level productivity
tools, such as forms and report generators, and high-level languages that automate
some of the activities of database design and implementation. We describe
many of these tools in subsequent chapters.
3. Significant improvement in application developer productivity, estimated to be as
high as 60 percent (Long, 2005), is currently being realized through the use of Web
services, based on the use of standard Internet protocols and a universally accepted
data format (XML). Web services and XML are covered in Chapter 8.
ENFORCEMENT OF STANDARDS
When the database approach is implemented with full management support, the database administration function should be granted singlepoint authority and responsibility for establishing and enforcing data standards. These standards will include naming conventions, data quality standards, and uniform procedures for accessing, updating, and protecting data. The data repository provides database administrators with a powerful set of tools for developing and enforcing these standards.
Unfortunately, the failure to implement a strong database administration function is perhaps the most common source of database failures in organizations. We describe the
database administration (and related data administration) functions in Chapter 11.
IMPROVED DATA QUALITY Concern with poor quality data is a common theme in strategic planning and database administration today. In fact, a recent report by The Data Warehousing Institute (TDWI) estimated that data quality problems currently cost U.S. businesses some $600 billion each year (www.tdwi.org/research/display.asp?ID=6589). The database approach provides a number of tools and processes to improve data quality. Two of the more important are the following:
1. Database designers can specify integrity constraints that are enforced by the
DBMS. A constraint is a rule that cannot be violated by database users. We describe
numerous types of constraints (also called “business rules”) in Chapters 2
and 3. If a customer places an order, the constraint that ensures that the customer
and the order remain associated is called a “relational integrity constraint,” and it
prevents an order from being entered without specifying who placed the order.
2. One of the objectives of a data warehouse environment is to clean up (or “scrub”)
operational data before they are placed in the data warehouse (Jordan, 1996). Do you
ever receive multiple copies of a catalog? The company that sends you three copies of
each of its mailings could recognize significant postage and printing savings if its
data were scrubbed, and its understanding of its customers would also be enhanced
if it could determine a more accurate count of existing customers. We describe data
warehouses in Chapter 9 and the potential for improving data quality in Chapter 10.
IMPROVED DATA ACCESSIBILITY AND RESPONSIVENESS
With a relational database, end users without programming experience can often retrieve and display data, even when it crosses traditional departmental boundaries. For example, an employee can display information about computer desks at Pine Valley Furniture Company with the following query:
The separation of data descriptions (metadata) from the application programs that use the data is called data independence. With the database approach, data descriptions are stored in a central location called the repository.
This property of database systems allows an organization’s data to change and evolve
(within limits) without changing the application programs that process the data.
PLANNED DATA REDUNDANCY
Good database design attempts to integrate previously separate (and redundant) data files into a single, logical structure. Ideally, each primary fact is recorded in only one place in the database. For example, facts about a product, such as Pine Valley oak computer desk, its finish, price, and so forth are recorded together in one place in the Product table, which contains data about each of Pine Valley’s products. The database approach does not eliminate redundancy entirely, but it enables the designer to control the type and amount of redundancy. At other times it may be desirable to include some limited redundancy to improve database performance, as we will see in later chapters.
IMPROVED DATA CONSISTENCY
By eliminating or controlling data redundancy, we greatly reduce the opportunities for inconsistency. For example, if a customer’s address is stored only once, we cannot disagree about the customer’s address. When the customer’s address changes, recording the new address is greatly simplified because the address is stored in a single place. Finally, we avoid the wasted storage space that results from redundant data storage.
IMPROVED DATA SHARING
A database is designed as a shared corporate resource. Authorized internal and external users are granted permission to use the database, and each user (or group of users) is provided one or more user views into the database to facilitate this use. Auser view is a logical description of some portion of the database that is required by a user to perform some task. A user view is often developed by identifying a form or report that the user needs on a regular basis. For example, an employee working in human resources will need access to confidential employee data; a customer needs access to the product catalog available on Pine Valley’s Web site. The views for the human resources employee and the customer are drawn from completely different areas of one unified database.
INCREASED PRODUCTIVITY OF APPLICATION DEVELOPMENT
A major advantage of the database approach is that it greatly reduces the cost and time for developing new business applications. There are three important reasons that database applications can often be developed much more rapidly than conventional file applications:
1. Assuming that the database and the related data capture and maintenance applications
have already been designed and implemented, the application developer
can concentrate on the specific functions required for the new application, without
having to worry about file design or low-level implementation details.
2. The database management system provides a number of high-level productivity
tools, such as forms and report generators, and high-level languages that automate
some of the activities of database design and implementation. We describe
many of these tools in subsequent chapters.
3. Significant improvement in application developer productivity, estimated to be as
high as 60 percent (Long, 2005), is currently being realized through the use of Web
services, based on the use of standard Internet protocols and a universally accepted
data format (XML). Web services and XML are covered in Chapter 8.
ENFORCEMENT OF STANDARDS
When the database approach is implemented with full management support, the database administration function should be granted singlepoint authority and responsibility for establishing and enforcing data standards. These standards will include naming conventions, data quality standards, and uniform procedures for accessing, updating, and protecting data. The data repository provides database administrators with a powerful set of tools for developing and enforcing these standards.
Unfortunately, the failure to implement a strong database administration function is perhaps the most common source of database failures in organizations. We describe the
database administration (and related data administration) functions in Chapter 11.
IMPROVED DATA QUALITY Concern with poor quality data is a common theme in strategic planning and database administration today. In fact, a recent report by The Data Warehousing Institute (TDWI) estimated that data quality problems currently cost U.S. businesses some $600 billion each year (www.tdwi.org/research/display.asp?ID=6589). The database approach provides a number of tools and processes to improve data quality. Two of the more important are the following:
1. Database designers can specify integrity constraints that are enforced by the
DBMS. A constraint is a rule that cannot be violated by database users. We describe
numerous types of constraints (also called “business rules”) in Chapters 2
and 3. If a customer places an order, the constraint that ensures that the customer
and the order remain associated is called a “relational integrity constraint,” and it
prevents an order from being entered without specifying who placed the order.
2. One of the objectives of a data warehouse environment is to clean up (or “scrub”)
operational data before they are placed in the data warehouse (Jordan, 1996). Do you
ever receive multiple copies of a catalog? The company that sends you three copies of
each of its mailings could recognize significant postage and printing savings if its
data were scrubbed, and its understanding of its customers would also be enhanced
if it could determine a more accurate count of existing customers. We describe data
warehouses in Chapter 9 and the potential for improving data quality in Chapter 10.
IMPROVED DATA ACCESSIBILITY AND RESPONSIVENESS
With a relational database, end users without programming experience can often retrieve and display data, even when it crosses traditional departmental boundaries. For example, an employee can display information about computer desks at Pine Valley Furniture Company with the following query:

The language used in this query is called Structured Query Language, or SQL. (You will
study this language in detail in Chapters 6 and 7.) Although the queries constructed can
be much more complex, the basic structure of the query is easy for even novice, nonprogrammers
to grasp. If they understand the structure and names of the data that fit
within their view of the database, they soon gain the ability to retrieve answers to new
questions without having to rely on a professional application developer. This can be
dangerous; queries should be thoroughly tested to be sure they are returning accurate
data before relying on their results, and novices may not understand that challenge
.
REDUCED PROGRAM MAINTENANCE
Stored data must be changed frequently for a variety of reasons: new data item types are added, data formats are changed, and so on. A celebrated example of this problem was the well-known “year 2000” problem, in which common two-digit year fields were extended to four digits to accommodate the rollover from the year 1999 to the year 2000.
In a file processing environment, the data descriptions and the logic for accessing
data are built into individual application programs (this is the program-data dependence
issue described earlier). As a result, changes to data formats and access methods
inevitably result in the need to modify application programs. In a database environment,
data are more independent of the application programs that use them. Within
limits, we can change either the data or the application programs that use the data without necessitating a change in the other factor. As a result, program maintenance can be significantly reduced in a modern database environment.
IMPROVED DECISION SUPPORT
Some databases are designed expressly for decision support applications. For example, some databases are designed to support customer relationship management, whereas others are designed to support financial analysis or supply chain management. You will study how databases are tailored for different decision support applications and analytical styles in Chapter 9.
study this language in detail in Chapters 6 and 7.) Although the queries constructed can
be much more complex, the basic structure of the query is easy for even novice, nonprogrammers
to grasp. If they understand the structure and names of the data that fit
within their view of the database, they soon gain the ability to retrieve answers to new
questions without having to rely on a professional application developer. This can be
dangerous; queries should be thoroughly tested to be sure they are returning accurate
data before relying on their results, and novices may not understand that challenge
.
REDUCED PROGRAM MAINTENANCE
Stored data must be changed frequently for a variety of reasons: new data item types are added, data formats are changed, and so on. A celebrated example of this problem was the well-known “year 2000” problem, in which common two-digit year fields were extended to four digits to accommodate the rollover from the year 1999 to the year 2000.
In a file processing environment, the data descriptions and the logic for accessing
data are built into individual application programs (this is the program-data dependence
issue described earlier). As a result, changes to data formats and access methods
inevitably result in the need to modify application programs. In a database environment,
data are more independent of the application programs that use them. Within
limits, we can change either the data or the application programs that use the data without necessitating a change in the other factor. As a result, program maintenance can be significantly reduced in a modern database environment.
IMPROVED DECISION SUPPORT
Some databases are designed expressly for decision support applications. For example, some databases are designed to support customer relationship management, whereas others are designed to support financial analysis or supply chain management. You will study how databases are tailored for different decision support applications and analytical styles in Chapter 9.

