Cautions About Database Benefits
The previous section identified 10 major potential benefits of the database approach.
However, we must caution you that many organizations have been frustrated
in attempting to realize some of these benefits. For example, the goal of data independence
(and, therefore, reduced program maintenance) has proven elusive due to
the limitations of older data models and database management software.
Fortunately, the relational model and the newer object-oriented model provide a
significantly better environment for achieving these benefits. Another reason for
failure to achieve the intended benefits is poor organizational planning and database
implementation; even the best data management software cannot overcome
such deficiencies. For this reason, we stress database planning and design throughout
this text.
Costs and Risks of the Database Approach
A database is not a silver bullet, and it does not have the magic power of Harry Potter.
As with any other business decision, the database approach entails some additional
costs and risks that must be recognized and managed when it is implemented (see
Table 1-4).
NEW, SPECIALIZED PERSONNEL Frequently, organizations that adopt the database approach
need to hire or train individuals to design and implement databases, provide
database administration services, and manage a staff of new people. Further, because of
the rapid changes in technology, these new people will have to be retrained or upgraded
on a regular basis. This personnel increase may be more than offset by other productivity
gains, but an organization should recognize the need for these specialized skills,
which are required to obtain the most from the potential benefits. We discuss the staff
requirements for database management in Chapter 11.
INSTALLATION AND MANAGEMENT COST AND COMPLEXITY
A multiuser database management system is a large and complex suite of software that has a high initial cost, requires a staff of trained personnel to install and operate, and has substantial annual maintenance and support costs. Installing such a system may also require upgrades to the hardware and data communications systems in the organization.
Substantial training is normally required on an ongoing basis to keep up with new releases and upgrades. Additional or more sophisticated and costly database software
may be needed to provide security and to ensure proper concurrent updating of
shared data.
CONVERSION COSTS
The term legacy system is widely used to refer to older applications in an organization that are based on file processing and/or older database technology. The cost of converting these older systems to modern database technology— measured in terms of dollars, time, and organizational commitment—may often seem prohibitive to an organization. The use of data warehouses is one strategy for continuing to use older systems while at the same time exploiting modern database technology and techniques (Ritter, 1999).
NEED FOR EXPLICIT BACKUP AND
RECOVERY
A shared corporate database must be accurate and available at all times. This requires that comprehensive procedures be developed and used for providing backup copies of data and for restoring a database when damage occurs. These considerations have acquired increased urgency in today’s security-conscious environment. A modern database management system normally automates many more of the backup and recovery tasks than a file system. We describe procedures for security, backup, and recovery in Chapter 11.
ORGANIZATIONAL CONFLICT
A shared database requires a consensus on data definitions and ownership, as well as responsibilities for accurate data maintenance. Experience has shown that conflicts on data definitions, data formats and coding, rights to update shared data, and associated issues are frequent and often difficult to resolve.
Handling these issues requires organizational commitment to the database approach,
organizationally astute database administrators, and a sound evolutionary approach to
database development.
If strong top management support of and commitment to the database approach is
lacking, end-user development of stand-alone databases is likely to proliferate. These
databases do not follow the general database approach that we have described, and
they are unlikely to provide the benefits described earlier. In the extreme, they may lead
to a pattern of inferior decision making that threatens the well-being or existence of an
organization.
COMPONENTS OF THE DATABASE ENVIRONMENT
Now that you have seen the advantages and risks of using the database approach to
managing data, let us examine the major components of a typical database environment
and their relationships (see Figure 1-5). You have already been introduced to some (but
not all) of these components in previous sections. Following is a brief description of the
nine components shown in Figure 1-5:
1. Computer-aided software engineering (CASE) tools CASE tools are automated
tools used to design databases and application programs. These tools help with
creation of data models and in some cases can also help automatically generate the
“code” needed to create the database. We reference the use of automated tools for
database design and development throughout the text.
2. Repository Arepository is a centralized knowledge base for all data definitions,
data relationships, screen and report formats, and other system components. A
repository contains an extended set of metadata important for managing databases
as well as other components of an information system. We describe the repository
in Chapter 11.
The previous section identified 10 major potential benefits of the database approach.
However, we must caution you that many organizations have been frustrated
in attempting to realize some of these benefits. For example, the goal of data independence
(and, therefore, reduced program maintenance) has proven elusive due to
the limitations of older data models and database management software.
Fortunately, the relational model and the newer object-oriented model provide a
significantly better environment for achieving these benefits. Another reason for
failure to achieve the intended benefits is poor organizational planning and database
implementation; even the best data management software cannot overcome
such deficiencies. For this reason, we stress database planning and design throughout
this text.
Costs and Risks of the Database Approach
A database is not a silver bullet, and it does not have the magic power of Harry Potter.
As with any other business decision, the database approach entails some additional
costs and risks that must be recognized and managed when it is implemented (see
Table 1-4).
NEW, SPECIALIZED PERSONNEL Frequently, organizations that adopt the database approach
need to hire or train individuals to design and implement databases, provide
database administration services, and manage a staff of new people. Further, because of
the rapid changes in technology, these new people will have to be retrained or upgraded
on a regular basis. This personnel increase may be more than offset by other productivity
gains, but an organization should recognize the need for these specialized skills,
which are required to obtain the most from the potential benefits. We discuss the staff
requirements for database management in Chapter 11.
INSTALLATION AND MANAGEMENT COST AND COMPLEXITY
A multiuser database management system is a large and complex suite of software that has a high initial cost, requires a staff of trained personnel to install and operate, and has substantial annual maintenance and support costs. Installing such a system may also require upgrades to the hardware and data communications systems in the organization.
Substantial training is normally required on an ongoing basis to keep up with new releases and upgrades. Additional or more sophisticated and costly database software
may be needed to provide security and to ensure proper concurrent updating of
shared data.
CONVERSION COSTS
The term legacy system is widely used to refer to older applications in an organization that are based on file processing and/or older database technology. The cost of converting these older systems to modern database technology— measured in terms of dollars, time, and organizational commitment—may often seem prohibitive to an organization. The use of data warehouses is one strategy for continuing to use older systems while at the same time exploiting modern database technology and techniques (Ritter, 1999).
NEED FOR EXPLICIT BACKUP AND
RECOVERY
A shared corporate database must be accurate and available at all times. This requires that comprehensive procedures be developed and used for providing backup copies of data and for restoring a database when damage occurs. These considerations have acquired increased urgency in today’s security-conscious environment. A modern database management system normally automates many more of the backup and recovery tasks than a file system. We describe procedures for security, backup, and recovery in Chapter 11.
ORGANIZATIONAL CONFLICT
A shared database requires a consensus on data definitions and ownership, as well as responsibilities for accurate data maintenance. Experience has shown that conflicts on data definitions, data formats and coding, rights to update shared data, and associated issues are frequent and often difficult to resolve.
Handling these issues requires organizational commitment to the database approach,
organizationally astute database administrators, and a sound evolutionary approach to
database development.
If strong top management support of and commitment to the database approach is
lacking, end-user development of stand-alone databases is likely to proliferate. These
databases do not follow the general database approach that we have described, and
they are unlikely to provide the benefits described earlier. In the extreme, they may lead
to a pattern of inferior decision making that threatens the well-being or existence of an
organization.
COMPONENTS OF THE DATABASE ENVIRONMENT
Now that you have seen the advantages and risks of using the database approach to
managing data, let us examine the major components of a typical database environment
and their relationships (see Figure 1-5). You have already been introduced to some (but
not all) of these components in previous sections. Following is a brief description of the
nine components shown in Figure 1-5:
1. Computer-aided software engineering (CASE) tools CASE tools are automated
tools used to design databases and application programs. These tools help with
creation of data models and in some cases can also help automatically generate the
“code” needed to create the database. We reference the use of automated tools for
database design and development throughout the text.
2. Repository Arepository is a centralized knowledge base for all data definitions,
data relationships, screen and report formats, and other system components. A
repository contains an extended set of metadata important for managing databases
as well as other components of an information system. We describe the repository
in Chapter 11.
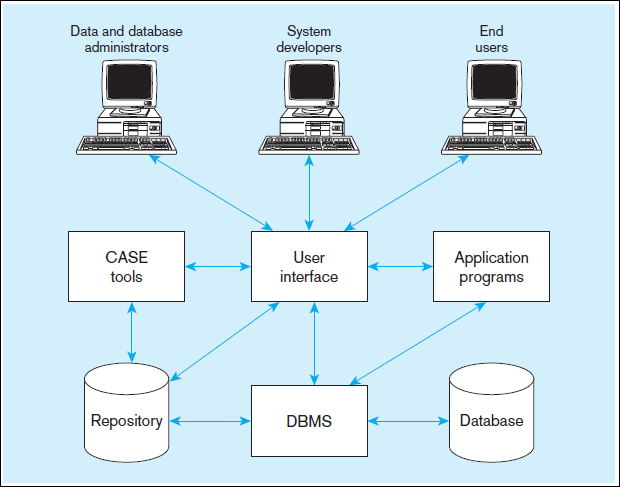
3. DBMS A DBMS is a software system that is used to create, maintain, and provide
controlled access to user databases. We describe the functions of a DBMS in
Chapter 11.
4. Database Adatabase is an organized collection of logically related data, usually
designed to meet the information needs of multiple users in an organization. It is
important to distinguish between the database and the repository. The repository
contains definitions of data, whereas the database contains occurrences of data.
We describe the activities of database design in Chapters 4 and 5 and of implementation
in Chapters 6 through 9.
5. Application programs Computer-based application programs are used to create
and maintain the database and provide information to users. Key database-related
application programming skills are described in Chapters 6 through 9 and
Chapter 14.
6. User interface The user interface includes languages, menus, and other facilities
by which users interact with various system components, such as CASE tools, application
programs, the DBMS, and the repository. User interfaces are illustrated
throughout this text.
7. Data and database administrators Data administrators are persons who are responsible
for the overall management of data resources in an organization.
Database administrators are responsible for physical database design and for
managing technical issues in the database environment. We describe these functions
in detail in Chapter 11.
8. System developers System developers are persons such as systems analysts and
programmers who design new application programs. System developers often
use CASE tools for system requirements analysis and program design.
9. End users End users are persons throughout the organization who add, delete,
and modify data in the database and who request or receive information from it.
All user interactions with the database must be routed through the DBMS.
In summary, the database operational environment shown in Figure 1-5 is an integrated
system of hardware, software, and people, designed to facilitate the storage, retrieval,
and control of the information resource and to improve the productivity of the
organization.
THE RANGE OF DATABASE APPLICATIONS
What can databases help us do? Figure 1-5 shows that there are several methods for
people to interact with the data in the database. First, users can interact directly with the
database using the user interface provided by the DBMS. In this manner users can issues
commands (called queries) against the database and examine the results or potentially
even store this inside a Microsoft Excel spreadsheet or Word document. This
method of interaction with the database is referred to ad-hoc querying and requires a
level of understanding the query language on the part of the user.
Because most business users do not possess this level of knowledge, the second
and more common mechanism for accessing the database is using application programs.
An application program consists of two key components. Agraphical user interface
that is used to accept the users’ request (e.g., to input, delete, or modify data)
and/or provide a mechanism for displaying the data retrieved from the database. The
business logic contains the programming logic necessary to act on the users’ commands.
The machine that runs the user interface (and sometimes the business logic) is
referred to as the client. The machine the runs the DBMS and contains the database is referred to as the database server.
It is important to understand that the applications and the database need not to reside
on the same computer (and, in most cases, they don’t). In order to better understand
the range of database applications, we divide them into three categories, based on
the location of the client (application) and the database software itself: personal, twotier,
and multitier databases. We introduce each category with a typical example, followed
by some issues that generally arise within that category of use.
Personal Databases
Personal databases are designed to support one user. Personal databases have long
resided on personal computers (PCs), including laptops, and increasingly on smartphones
and PDAs. The purpose of these databases is to provide the user with ability
to manage (store, update, delete, and retrieve) small amounts of data in an efficient
manner. Simple database applications that store customer information and the details
of contacts with each customer can be used from a PC and easily transferred
from one device to the other for backup and work purposes. For example, consider a
company that has a number of salespersons who call on actual or prospective customers.
A database of customers and a pricing application can enable the salesperson
to determine the best combination of quantity and type of items for the customer to
order.Personal databases are widely used because they can often improve personal productivity.
However, they entail a risk: The data cannot easily be shared with other users.
For example, suppose the sales manager wants a consolidated view of customer contacts.
This cannot be quickly or easily provided from an individual salesperson’s databases.
This illustrates a very common problem: If data are of interest to one person, they probably are or will soon become of interest to others as well. For this reason, personal databases
should be limited to those rather special situations (e.g., in a very small organization)
where the need to share the data among users of the personal database is unlikely to arise.
Two-Tier Client/Server Databases
As noted above, the utility of a personal (single-user) database is quite limited. Often,
what starts off as a single-user database evolves into something that needs to be shared
among several users. Aworkgroup is a relatively small team of people (typically fewer
than 25 persons) who collaborate on the same project or application or on a group of
similar projects or applications. These persons might be engaged (for example) with a
construction project or with developing a new computer application and need to share
data amongst the group.
The most common method of sharing data for this type of need is based on creating
a two-tier client/server application as shown in Figure 1-6. Each member of the workgroup has a computer, and the computers are linked by means of network (wired or
wireless LAN). In most cases, each computer has a copy of a specialized application
(client) which provides the user interface as well as the business logic through which the
data is manipulated. The database itself and the DBMS are stored on a central device called the “database server,” which is also connected to the network. Thus, each member of the workgroup has access to the shared data. Different types of group members (e.g.,developer or project manager) may have different user views of this shared database.This arrangement overcomes the principal objection to PC databases, which is that thedata are not easily shared. This arrangement, however, introduces many data management issues not present with personal (single-user) databases, such as data security and data integrity when multiple users attempt to change and update data at the same time.
controlled access to user databases. We describe the functions of a DBMS in
Chapter 11.
4. Database Adatabase is an organized collection of logically related data, usually
designed to meet the information needs of multiple users in an organization. It is
important to distinguish between the database and the repository. The repository
contains definitions of data, whereas the database contains occurrences of data.
We describe the activities of database design in Chapters 4 and 5 and of implementation
in Chapters 6 through 9.
5. Application programs Computer-based application programs are used to create
and maintain the database and provide information to users. Key database-related
application programming skills are described in Chapters 6 through 9 and
Chapter 14.
6. User interface The user interface includes languages, menus, and other facilities
by which users interact with various system components, such as CASE tools, application
programs, the DBMS, and the repository. User interfaces are illustrated
throughout this text.
7. Data and database administrators Data administrators are persons who are responsible
for the overall management of data resources in an organization.
Database administrators are responsible for physical database design and for
managing technical issues in the database environment. We describe these functions
in detail in Chapter 11.
8. System developers System developers are persons such as systems analysts and
programmers who design new application programs. System developers often
use CASE tools for system requirements analysis and program design.
9. End users End users are persons throughout the organization who add, delete,
and modify data in the database and who request or receive information from it.
All user interactions with the database must be routed through the DBMS.
In summary, the database operational environment shown in Figure 1-5 is an integrated
system of hardware, software, and people, designed to facilitate the storage, retrieval,
and control of the information resource and to improve the productivity of the
organization.
THE RANGE OF DATABASE APPLICATIONS
What can databases help us do? Figure 1-5 shows that there are several methods for
people to interact with the data in the database. First, users can interact directly with the
database using the user interface provided by the DBMS. In this manner users can issues
commands (called queries) against the database and examine the results or potentially
even store this inside a Microsoft Excel spreadsheet or Word document. This
method of interaction with the database is referred to ad-hoc querying and requires a
level of understanding the query language on the part of the user.
Because most business users do not possess this level of knowledge, the second
and more common mechanism for accessing the database is using application programs.
An application program consists of two key components. Agraphical user interface
that is used to accept the users’ request (e.g., to input, delete, or modify data)
and/or provide a mechanism for displaying the data retrieved from the database. The
business logic contains the programming logic necessary to act on the users’ commands.
The machine that runs the user interface (and sometimes the business logic) is
referred to as the client. The machine the runs the DBMS and contains the database is referred to as the database server.
It is important to understand that the applications and the database need not to reside
on the same computer (and, in most cases, they don’t). In order to better understand
the range of database applications, we divide them into three categories, based on
the location of the client (application) and the database software itself: personal, twotier,
and multitier databases. We introduce each category with a typical example, followed
by some issues that generally arise within that category of use.
Personal Databases
Personal databases are designed to support one user. Personal databases have long
resided on personal computers (PCs), including laptops, and increasingly on smartphones
and PDAs. The purpose of these databases is to provide the user with ability
to manage (store, update, delete, and retrieve) small amounts of data in an efficient
manner. Simple database applications that store customer information and the details
of contacts with each customer can be used from a PC and easily transferred
from one device to the other for backup and work purposes. For example, consider a
company that has a number of salespersons who call on actual or prospective customers.
A database of customers and a pricing application can enable the salesperson
to determine the best combination of quantity and type of items for the customer to
order.Personal databases are widely used because they can often improve personal productivity.
However, they entail a risk: The data cannot easily be shared with other users.
For example, suppose the sales manager wants a consolidated view of customer contacts.
This cannot be quickly or easily provided from an individual salesperson’s databases.
This illustrates a very common problem: If data are of interest to one person, they probably are or will soon become of interest to others as well. For this reason, personal databases
should be limited to those rather special situations (e.g., in a very small organization)
where the need to share the data among users of the personal database is unlikely to arise.
Two-Tier Client/Server Databases
As noted above, the utility of a personal (single-user) database is quite limited. Often,
what starts off as a single-user database evolves into something that needs to be shared
among several users. Aworkgroup is a relatively small team of people (typically fewer
than 25 persons) who collaborate on the same project or application or on a group of
similar projects or applications. These persons might be engaged (for example) with a
construction project or with developing a new computer application and need to share
data amongst the group.
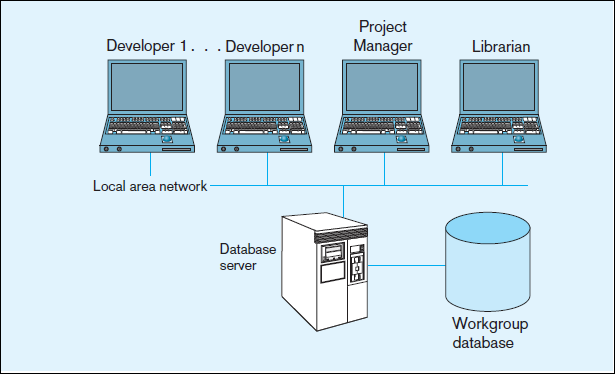
The most common method of sharing data for this type of need is based on creating
a two-tier client/server application as shown in Figure 1-6. Each member of the workgroup has a computer, and the computers are linked by means of network (wired or
wireless LAN). In most cases, each computer has a copy of a specialized application
(client) which provides the user interface as well as the business logic through which the
data is manipulated. The database itself and the DBMS are stored on a central device called the “database server,” which is also connected to the network. Thus, each member of the workgroup has access to the shared data. Different types of group members (e.g.,developer or project manager) may have different user views of this shared database.This arrangement overcomes the principal objection to PC databases, which is that thedata are not easily shared. This arrangement, however, introduces many data management issues not present with personal (single-user) databases, such as data security and data integrity when multiple users attempt to change and update data at the same time.
Multitier Client/Server Databases
One of the drawbacks of the two-tier database architecture is that the amount of functionality that needs to be programmed into the application on the users’ computer can be pretty significant because it needs to contain both the user interface logic as well as the business logic. This, of course, means that the client computers need to be powerful enough to handle the programmed application. Another drawback is that each time there is a change to either the business logic or user interface, each client computer that has the application needs to be updated.
To overcome these limitations, most modern applications that need to support a
large number of users are built using the concept of multitiered architecture. In most organizations, these applications are intended to support a department (such as marketing or accounting) or a division (such as a line of business), which is generally larger than a workgroup (typically between 25 and 100 persons).
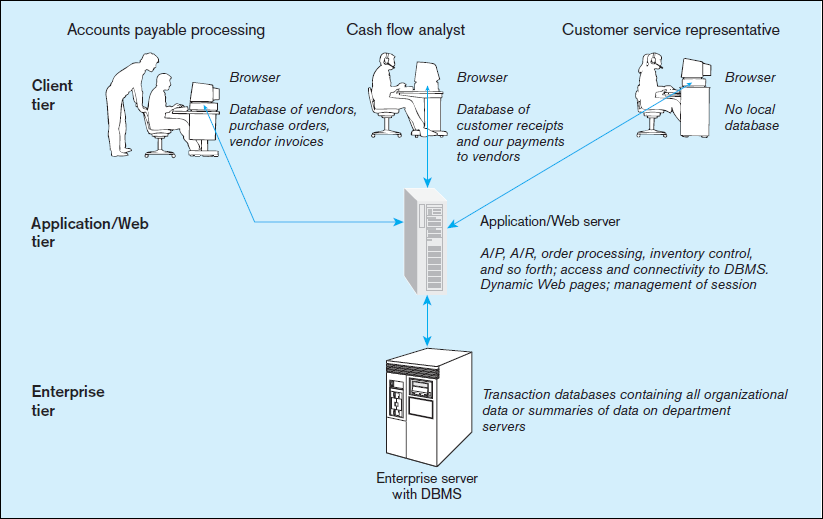
An example of a company that has several multitier applications is shown in
Figure 1-7. In a three-tiered architecture, the user interface is accessible on the individual
users’ computer. This user interface may either be Web browser based or written using
programming languages such as Visual Basic.NET, Visual C#, or Java. The application
layer/Web server layer contains the business logic required to accomplish the business
transactions requested by the users. This layer in turn talks to the database server. The most significant implication for database development from the use of multitier
client/server architectures is the ease of separating the development of the database and
the modules that maintain the data from the information systems modules that focus on
business logic and/or presentation logic. In addition, this architecture allows us to improve performance and maintainability of the application and database. We will consider both two and multitier client/server architectures in more detail in Chapter 8.
One of the drawbacks of the two-tier database architecture is that the amount of functionality that needs to be programmed into the application on the users’ computer can be pretty significant because it needs to contain both the user interface logic as well as the business logic. This, of course, means that the client computers need to be powerful enough to handle the programmed application. Another drawback is that each time there is a change to either the business logic or user interface, each client computer that has the application needs to be updated.
To overcome these limitations, most modern applications that need to support a
large number of users are built using the concept of multitiered architecture. In most organizations, these applications are intended to support a department (such as marketing or accounting) or a division (such as a line of business), which is generally larger than a workgroup (typically between 25 and 100 persons).
An example of a company that has several multitier applications is shown in
Figure 1-7. In a three-tiered architecture, the user interface is accessible on the individual
users’ computer. This user interface may either be Web browser based or written using
programming languages such as Visual Basic.NET, Visual C#, or Java. The application
layer/Web server layer contains the business logic required to accomplish the business
transactions requested by the users. This layer in turn talks to the database server. The most significant implication for database development from the use of multitier
client/server architectures is the ease of separating the development of the database and
the modules that maintain the data from the information systems modules that focus on
business logic and/or presentation logic. In addition, this architecture allows us to improve performance and maintainability of the application and database. We will consider both two and multitier client/server architectures in more detail in Chapter 8.