The world has become a very complex place. The advantage goes to people and organizations that collect, manage, and interpret information effectively. To make our point, let’s visit Continental Airlines. A little over a decade ago, Continental was in real trouble, ranking at the bottom of U.S. airlines in on-time performance, mishandled baggage, customer complaints, and overbooking. Speculation was that Continental would have to file for bankruptcy for the third time. In the past 10 years, Continental had had 10 CEOs. Could more effective collection, management, and interpretation of Continental’s data and information help Continental’s situation? The answer is a definite yes. Today Continental is one of the most respected global airlines and has been named the Most Admired Global Airline on Fortune magazine’s list of Most Admired Global Companies annually since 2004. It was recognized as Best Airline Based in North America and the airline with the Best Airline Finance Deal by the 2008 OAG Airline of the Year awards. Continental’s former chairman of the board and CEO, Larry Kellner, points to the use of real-time business intelligence as a significant factor in Continental’s turnaround. How? Implementation of a real-time or “active” data warehouse has supported the company’s business strategy, dramatically improving customer service and operations, creating cost savings, and generating revenue. Fifteen years ago,
Continental could not even track a customer’s travel itinerary if more than one stop
was involved. Now, employees who deal with travelers know if a high-value customer
is currently experiencing a delay in a trip, where and when the customer will arrive at
the airport, and the gate where the customer must go to make the next airline connection. High-value customers receive letters of apology if they experience travel delays on Continental and sometimes a trial membership in the President’s Club.
Following is a list of some of the wins that came from integrating revenue, flight schedule, customer, inventory, and security data as part of the data
warehousing project:
1. Better optimization of airfares using mathematical programming models that
are able to adjust the number of seats sold at a particular fare using real-time
sales data
2. Improvement of customer relationship management focused on Continental’s
most profitable customers
3. Immediate availability of customer profiles to sales personnel, marketing
managers, and flight personnel, such as ticket agents and flight attendants
4. Support for union negotiations, including analysis of pilot staffing that allows
management and union negotiators to evaluate the appropriateness of work
assignment decisions
5. Development of fraud profiles that can be run against the data to identify
transactions that appear to fit one of over 100 fraud profiles
To emphasize this last win, Continental’s ability to meet Homeland Security
requirements has been greatly aided by the real-time data warehouse. During the
period immediately following the terrorist attacks of September 11, 2001,
Continental was able to work with the FBI to determine whether any terrorists on
the FBI watch list were attempting to board Continental flights. The data
warehouse’s ability to identify fraudulent activity and monitor passengers
contributes significantly to Continental’s goal of keeping all its passengers and
crew members safe (Anderson-Lehman et al., 2004).
Continental’s turnaround has been based on its corporate culture, which places
a high value on customer service and the effective use of information through the
integration of data in the data warehouse. Data do, indeed, matter. The topics
covered in this textbook will equip you with a deeper understanding of data and
how to collect, organize, and manage data. This understanding will give you the
power to support any business strategy and the deep satisfaction that comes from
knowing how to organize data so that financial, marketing, or customer service
questions can be answered almost as soon as they are asked. Enjoy!
INTRODUCTION
Over the past two decades there has been enormous growth in the number and
importance of database applications. Databases are used to store, manipulate, and
retrieve data in nearly every type of organization, including business, health care,
education, government, and libraries. Database technology is routinely used by
individuals on personal computers, by workgroups accessing databases on network servers, and by employees using enterprise-wide distributed applications.
Databases are also accessed by customers and other remote users through diverse
technologies, such as automated teller machines, Web browsers, smartphones, and
intelligent living and office environments. Most Web-based applications depend
on a database foundation.
Following this period of rapid growth, will the demand for databases and
database technology level off? Very likely not! In the highly competitive
environment of the early 2000s, there is every indication that database technology
will assume even greater importance. Managers seek to use knowledge derived
from databases for competitive advantage. For example, detailed sales databases
can be mined to determine customer buying patterns as a basis for advertising and
marketing campaigns. Organizations embed procedures called alerts in databases to
warn of unusual conditions, such as impending stock shortages or opportunities to
sell additional products, and to trigger appropriate actions.
Although the future of databases is assured, much work remains to be done.
Many organizations have a proliferation of incompatible databases that were
developed to meet immediate needs rather than based on a planned strategy or a
well-managed evolution. Enormous amounts of data are trapped in older, “legacy”
systems, and the data are often of poor quality. New skills are required to design
and manage data warehouses and to integrate databases with Internet
applications. There is a shortage of skills in areas such as database analysis, database
design, data administration, and database administration. We address these and
other important issues in this textbook to equip you for the jobs of the future.
A course in database management has emerged as one of the most important
courses in the information systems curriculum today. Many schools have added an
additional elective course in data warehousing or database administration to
provide in-depth coverage of these important topics. As information systems
professionals, you must be prepared to analyze database requirements and design
and implement databases within the context of information systems development.
You also must be prepared to consult with end users and show them how they can
use databases (or data warehouses) to build decision support systems and
executive information systems for competitive advantage. And, the widespread
use of databases attached to Web sites that return dynamic information to users of
these sites requires that you understand not only how to link databases to the Webbased
applications but also how to secure those databases so that their contents
can be viewed but not compromised by outside users.
In this chapter, we introduce the basic concepts of databases and database
management systems (DBMSs). We describe traditional file management systems
and some of their shortcomings that led to the database approach. Next, we
consider the benefits, costs, and risks of using the database approach. We review
of the range of technologies used to build, use, and manage databases, describe
the types of applications that use databases—personal, two-tier, three-tier, and
enterprise—and describe how databases have evolved over the past five decades.
Because a database is one part of an information system, this chapter also
examines how the database development process fits into the overall information
systems development process. The chapter emphasizes the need to coordinate
database development with all the other activities in the development of a complete
information system. It includes highlights from a hypothetical database development
process at Pine Valley Furniture Company. Using this example, the chapter introduces
tools for developing databases on personal computers and the process of extracting
data from enterprise databases for use in stand-alone applications.
There are several reasons for discussing database development at this point. First,
although you may have used the basic capabilities of a database management system,
such as Microsoft Access, you may not yet have developed an understanding of how
these databases were developed. Using simple examples, this chapter briefly
illustrates what you will be able to do after you complete a database course using this
text. Thus, this chapter helps you to develop a vision and context for each topic
developed in detail in subsequent chapters.
Second, many students learn best from a text full of concrete examples.
Although all of the chapters in this text contain numerous examples, illustrations,
and actual database designs and code, each chapter concentrates on a specific
aspect of database management. We have designed this chapter to help you
understand, with minimal technical details, how all of these individual aspects of
database management are related and how database development tasks and
skills relate to what you are learning in other information systems courses.
Finally, many instructors want you to begin the initial steps of a database
development group or individual project early in your database course. This chapter
gives you an idea of how to structure a database development project sufficient to
begin a course exercise. Obviously, because this is only the first chapter, many of the
examples and notations we will use will be much simpler than those required for
your project, for other course assignments, or in a real organization.
One note of caution: You will not learn how to design or develop databases
just from this chapter. Sorry! We have purposely kept the content of this chapter
introductory and simplified. Many of the notations used in this chapter are not
exactly like the ones you will learn in subsequent chapters. Our purpose in this
chapter is to give you a general understanding of the key steps and types of skills,
not to teach you specific techniques. You will, however, learn fundamental
concepts and definitions and develop an intuition and motivation for the skills and
knowledge presented in later chapters.
BASIC CONCEPTS AND DEFINITIONS
We define a database as an organized collection of logically related data. Not many
words in the definition, but have you looked at the size of this book? There is a lot to do
to fulfill this definition.
A database may be of any size and complexity. For example, a salesperson may
maintain a small database of customer contacts—consisting of a few megabytes of
data—on her laptop computer. A large corporation may build a large database consisting
of several terabytes of data (a terabyte is a trillion bytes) on a large mainframe
computer that is used for decision support applications (Winter, 1997). Very large data
warehouses contain more than a petabyte of data. (A petabyte is a quadrillion bytes.) (We
assume throughout the text that all databases are computer based.)
Data
Historically, the term data referred to facts concerning objects and events that could be
recorded and stored on computer media. For example, in a salesperson’s database, the
data would include facts such as customer name, address, and telephone number. This
type of data is called structured data. The most important structured data types are numeric, character, and dates. Structured data are stored in tabular form (in tables, relations, arrays, spreadsheets, etc.) and are most commonly found in traditional databases and data warehouses.
The traditional definition of data now needs to be expanded to reflect a new reality:
Databases today are used to store objects such as documents, e-mails, maps,
photographic images, sound, and video segments in addition to structured data. For
example, the salesperson’s database might include a photo image of the customer
contact. It might also include a sound recording or video clip about the most recent
product. This type of data is referred to as unstructured data, or as multimedia data.
Today structured and unstructured data are often combined in the same database to
create a true multimedia environment. For example, an automobile repair shop can
combine structured data (describing customers and automobiles) with multimedia
data (photo images of the damaged autos and scanned images of insurance claim
forms).
An expanded definition of data that includes structured and unstructured types is
“a stored representation of objects and events that have meaning and importance in the
user’s environment.”
Data Versus Information
The terms data and information are closely related, and in fact are often used interchangeably.
However, it is useful to distinguish between data and information. We define
information as data that have been processed in such a way that the knowledge of the
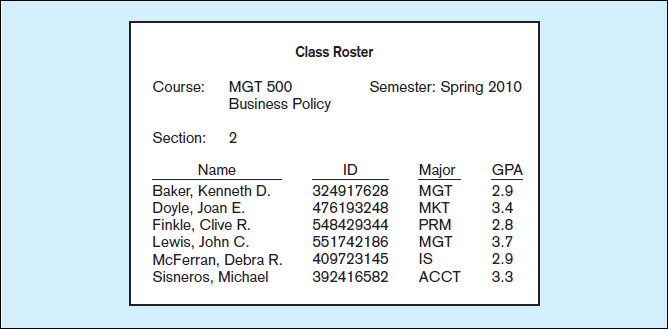
person who uses the data is increased. For example, consider the following list of facts:
Baker, Kenneth D. 324917628
Doyle, Joan E. 476193248
Finkle, Clive R. 548429344
Lewis, John C. 551742186
McFerran, Debra R. 409723145
These facts satisfy our definition of data, but most people would agree that the
data are useless in their present form. Even if we guess that this is a list of people’s
names paired with their Social Security numbers, the data remain useless because we
have no idea what the entries mean. Notice what happens when we place the same data
in a context, as shown in Figure 1-1a.
By adding a few additional data items and providing some structure, we recognize
a class roster for a particular course. This is useful information to some users, such
as the course instructor and the registrar’s office. Of course, as general awareness of the
importance of strong data security has increased, few organizations still use Social
Security numbers as identifiers. Instead, most organizations use an internally generated
number for identification purposes.
Data in context
Continental could not even track a customer’s travel itinerary if more than one stop
was involved. Now, employees who deal with travelers know if a high-value customer
is currently experiencing a delay in a trip, where and when the customer will arrive at
the airport, and the gate where the customer must go to make the next airline connection. High-value customers receive letters of apology if they experience travel delays on Continental and sometimes a trial membership in the President’s Club.
Following is a list of some of the wins that came from integrating revenue, flight schedule, customer, inventory, and security data as part of the data
warehousing project:
1. Better optimization of airfares using mathematical programming models that
are able to adjust the number of seats sold at a particular fare using real-time
sales data
2. Improvement of customer relationship management focused on Continental’s
most profitable customers
3. Immediate availability of customer profiles to sales personnel, marketing
managers, and flight personnel, such as ticket agents and flight attendants
4. Support for union negotiations, including analysis of pilot staffing that allows
management and union negotiators to evaluate the appropriateness of work
assignment decisions
5. Development of fraud profiles that can be run against the data to identify
transactions that appear to fit one of over 100 fraud profiles
To emphasize this last win, Continental’s ability to meet Homeland Security
requirements has been greatly aided by the real-time data warehouse. During the
period immediately following the terrorist attacks of September 11, 2001,
Continental was able to work with the FBI to determine whether any terrorists on
the FBI watch list were attempting to board Continental flights. The data
warehouse’s ability to identify fraudulent activity and monitor passengers
contributes significantly to Continental’s goal of keeping all its passengers and
crew members safe (Anderson-Lehman et al., 2004).
Continental’s turnaround has been based on its corporate culture, which places
a high value on customer service and the effective use of information through the
integration of data in the data warehouse. Data do, indeed, matter. The topics
covered in this textbook will equip you with a deeper understanding of data and
how to collect, organize, and manage data. This understanding will give you the
power to support any business strategy and the deep satisfaction that comes from
knowing how to organize data so that financial, marketing, or customer service
questions can be answered almost as soon as they are asked. Enjoy!
INTRODUCTION
Over the past two decades there has been enormous growth in the number and
importance of database applications. Databases are used to store, manipulate, and
retrieve data in nearly every type of organization, including business, health care,
education, government, and libraries. Database technology is routinely used by
individuals on personal computers, by workgroups accessing databases on network servers, and by employees using enterprise-wide distributed applications.
Databases are also accessed by customers and other remote users through diverse
technologies, such as automated teller machines, Web browsers, smartphones, and
intelligent living and office environments. Most Web-based applications depend
on a database foundation.
Following this period of rapid growth, will the demand for databases and
database technology level off? Very likely not! In the highly competitive
environment of the early 2000s, there is every indication that database technology
will assume even greater importance. Managers seek to use knowledge derived
from databases for competitive advantage. For example, detailed sales databases
can be mined to determine customer buying patterns as a basis for advertising and
marketing campaigns. Organizations embed procedures called alerts in databases to
warn of unusual conditions, such as impending stock shortages or opportunities to
sell additional products, and to trigger appropriate actions.
Although the future of databases is assured, much work remains to be done.
Many organizations have a proliferation of incompatible databases that were
developed to meet immediate needs rather than based on a planned strategy or a
well-managed evolution. Enormous amounts of data are trapped in older, “legacy”
systems, and the data are often of poor quality. New skills are required to design
and manage data warehouses and to integrate databases with Internet
applications. There is a shortage of skills in areas such as database analysis, database
design, data administration, and database administration. We address these and
other important issues in this textbook to equip you for the jobs of the future.
A course in database management has emerged as one of the most important
courses in the information systems curriculum today. Many schools have added an
additional elective course in data warehousing or database administration to
provide in-depth coverage of these important topics. As information systems
professionals, you must be prepared to analyze database requirements and design
and implement databases within the context of information systems development.
You also must be prepared to consult with end users and show them how they can
use databases (or data warehouses) to build decision support systems and
executive information systems for competitive advantage. And, the widespread
use of databases attached to Web sites that return dynamic information to users of
these sites requires that you understand not only how to link databases to the Webbased
applications but also how to secure those databases so that their contents
can be viewed but not compromised by outside users.
In this chapter, we introduce the basic concepts of databases and database
management systems (DBMSs). We describe traditional file management systems
and some of their shortcomings that led to the database approach. Next, we
consider the benefits, costs, and risks of using the database approach. We review
of the range of technologies used to build, use, and manage databases, describe
the types of applications that use databases—personal, two-tier, three-tier, and
enterprise—and describe how databases have evolved over the past five decades.
Because a database is one part of an information system, this chapter also
examines how the database development process fits into the overall information
systems development process. The chapter emphasizes the need to coordinate
database development with all the other activities in the development of a complete
information system. It includes highlights from a hypothetical database development
process at Pine Valley Furniture Company. Using this example, the chapter introduces
tools for developing databases on personal computers and the process of extracting
data from enterprise databases for use in stand-alone applications.
There are several reasons for discussing database development at this point. First,
although you may have used the basic capabilities of a database management system,
such as Microsoft Access, you may not yet have developed an understanding of how
these databases were developed. Using simple examples, this chapter briefly
illustrates what you will be able to do after you complete a database course using this
text. Thus, this chapter helps you to develop a vision and context for each topic
developed in detail in subsequent chapters.
Second, many students learn best from a text full of concrete examples.
Although all of the chapters in this text contain numerous examples, illustrations,
and actual database designs and code, each chapter concentrates on a specific
aspect of database management. We have designed this chapter to help you
understand, with minimal technical details, how all of these individual aspects of
database management are related and how database development tasks and
skills relate to what you are learning in other information systems courses.
Finally, many instructors want you to begin the initial steps of a database
development group or individual project early in your database course. This chapter
gives you an idea of how to structure a database development project sufficient to
begin a course exercise. Obviously, because this is only the first chapter, many of the
examples and notations we will use will be much simpler than those required for
your project, for other course assignments, or in a real organization.
One note of caution: You will not learn how to design or develop databases
just from this chapter. Sorry! We have purposely kept the content of this chapter
introductory and simplified. Many of the notations used in this chapter are not
exactly like the ones you will learn in subsequent chapters. Our purpose in this
chapter is to give you a general understanding of the key steps and types of skills,
not to teach you specific techniques. You will, however, learn fundamental
concepts and definitions and develop an intuition and motivation for the skills and
knowledge presented in later chapters.
BASIC CONCEPTS AND DEFINITIONS
We define a database as an organized collection of logically related data. Not many
words in the definition, but have you looked at the size of this book? There is a lot to do
to fulfill this definition.
A database may be of any size and complexity. For example, a salesperson may
maintain a small database of customer contacts—consisting of a few megabytes of
data—on her laptop computer. A large corporation may build a large database consisting
of several terabytes of data (a terabyte is a trillion bytes) on a large mainframe
computer that is used for decision support applications (Winter, 1997). Very large data
warehouses contain more than a petabyte of data. (A petabyte is a quadrillion bytes.) (We
assume throughout the text that all databases are computer based.)
Data
Historically, the term data referred to facts concerning objects and events that could be
recorded and stored on computer media. For example, in a salesperson’s database, the
data would include facts such as customer name, address, and telephone number. This
type of data is called structured data. The most important structured data types are numeric, character, and dates. Structured data are stored in tabular form (in tables, relations, arrays, spreadsheets, etc.) and are most commonly found in traditional databases and data warehouses.
The traditional definition of data now needs to be expanded to reflect a new reality:
Databases today are used to store objects such as documents, e-mails, maps,
photographic images, sound, and video segments in addition to structured data. For
example, the salesperson’s database might include a photo image of the customer
contact. It might also include a sound recording or video clip about the most recent
product. This type of data is referred to as unstructured data, or as multimedia data.
Today structured and unstructured data are often combined in the same database to
create a true multimedia environment. For example, an automobile repair shop can
combine structured data (describing customers and automobiles) with multimedia
data (photo images of the damaged autos and scanned images of insurance claim
forms).
An expanded definition of data that includes structured and unstructured types is
“a stored representation of objects and events that have meaning and importance in the
user’s environment.”
Data Versus Information
The terms data and information are closely related, and in fact are often used interchangeably.
However, it is useful to distinguish between data and information. We define
information as data that have been processed in such a way that the knowledge of the
person who uses the data is increased. For example, consider the following list of facts:
Baker, Kenneth D. 324917628
Doyle, Joan E. 476193248
Finkle, Clive R. 548429344
Lewis, John C. 551742186
McFerran, Debra R. 409723145
These facts satisfy our definition of data, but most people would agree that the
data are useless in their present form. Even if we guess that this is a list of people’s
names paired with their Social Security numbers, the data remain useless because we
have no idea what the entries mean. Notice what happens when we place the same data
in a context, as shown in Figure 1-1a.
By adding a few additional data items and providing some structure, we recognize
a class roster for a particular course. This is useful information to some users, such
as the course instructor and the registrar’s office. Of course, as general awareness of the
importance of strong data security has increased, few organizations still use Social
Security numbers as identifiers. Instead, most organizations use an internally generated
number for identification purposes.
Data in context
Summarized data
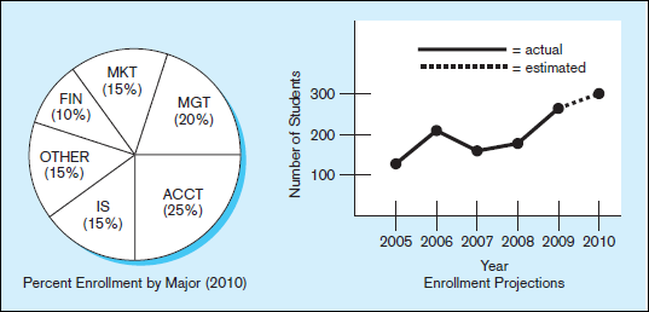
Another way to convert data into information is to summarize them or otherwise
process and present them for human interpretation. For example, Figure 1-1b shows
summarized student enrollment data presented as graphical information. This information could be used as a basis for deciding whether to add new courses or to hire new faculty members.
In practice, according to our definitions, databases today may contain either
data or information (or both). For example, a database may contain an image of the
class roster document shown in Figure 1-1a. Also, data are often preprocessed and
stored in summarized form in databases that are used for decision support.
Throughout this text we use the term database without distinguishing its contents as
data or information.
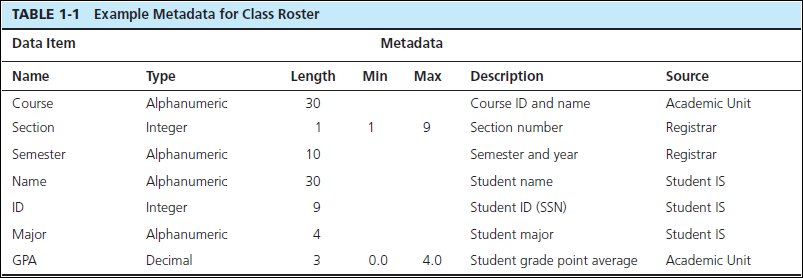
Metadata
As we have indicated, data become useful only when placed in some context. The
primary mechanism for providing context for data is metadata. Metadata are data
that describe the properties or characteristics of end-user data and the context of that
data. Some of the properties that are typically described include data names, definitions,
length (or size), and allowable values. Metadata describing data context include
the source of the data, where the data are stored, ownership (or stewardship),
and usage. Although it may seem circular, many people think of metadata as “data
about data.”
Some sample metadata for the Class Rster (Figure 1-1a) are listed in Table 1-1. For
each data item that appears in the Class Roster, the metadata show the data item name,
the data type, length, minimum and maximum allowable values (where appropriate), a
brief description of each data item, and the source of the data (sometimes called the
system of record). Notice the distinction between data and metadata. Metadata are once
removed from data. That is, metadata describe the properties of data but are separate
from that data. Thus, the metadata shown in Table 1-1 do not include any sample data
from the Class Roster of Figure 1-1a. Metadata enable database designers and users to
understand what data exist, what the data mean, and how to distinguish between data
items that at first glance look similar. Managing metadata is at least as crucial as managing the associated data because data without clear meaning can be confusing, misinterpreted, or erroneous. Typically, much of the metadata are stored as part of the
database and may be retrieved using the same approaches that are used to retrieve data
or information.Data can be stored in files or in databases. In the following sections we examine the progression from file processing systems to databases and the advantages and disadvantages of each.